
HybridClaw Dokumentation
Observability für KI-Agenten
Metrics-Taxonomy, KPIs, Cost- & Safety-Telemetry — eingebaut in die Runtime, nicht aufgesteckt.
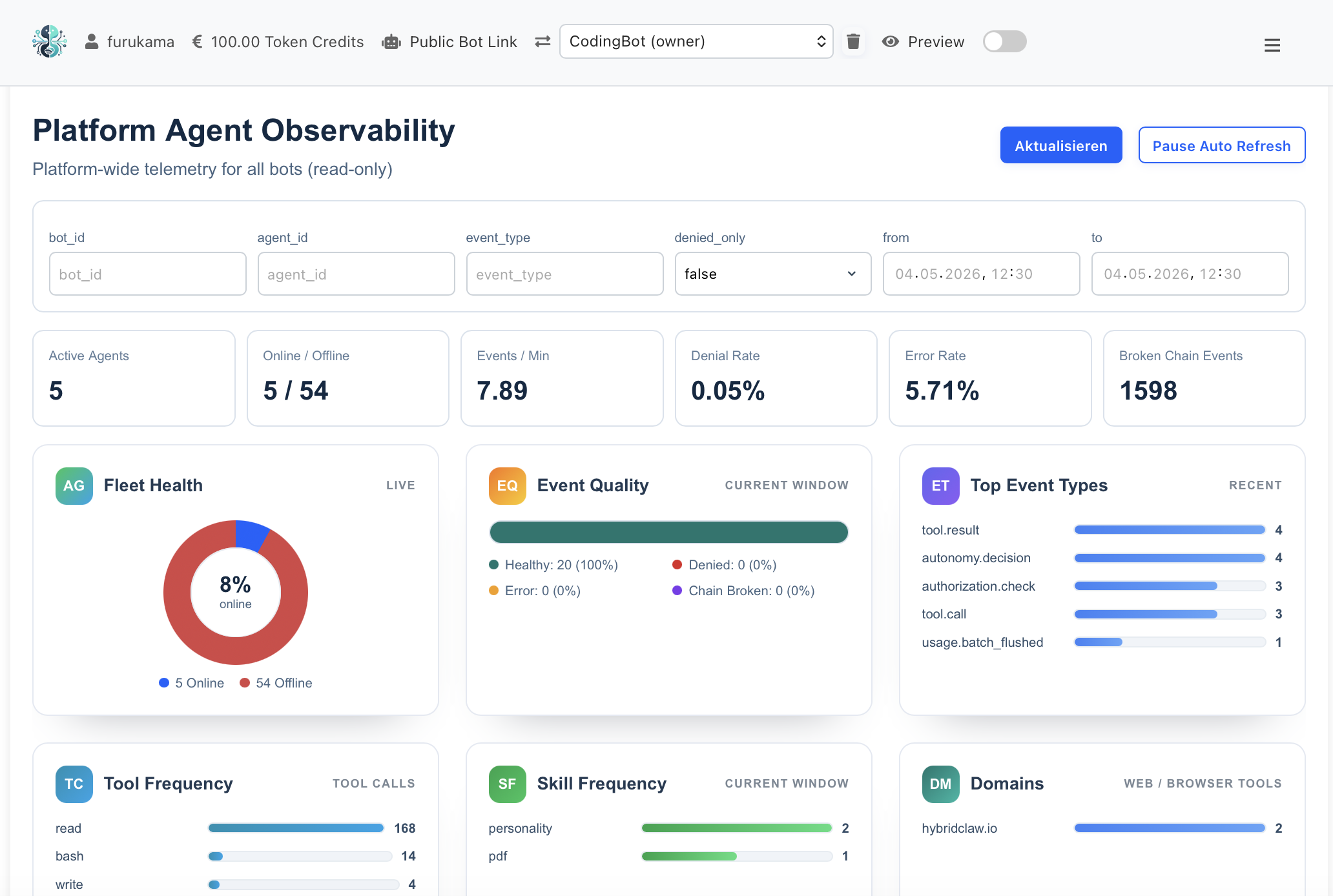
Live Monitoring Dashboard — Gateway, Agent & Execution Spans
Metrics Taxonomy
Jeder Span, jeder Tool-Call, jede Modell-Invocation emittiert strukturierte Telemetrie. Die Taxonomy ist stabil, dokumentiert und konsistent über Agenten hinweg — Dashboards, Alerts und SLOs funktionieren gleich für jedes Team.
| Metric | Was es misst | Aggregation | Typische Alert-Schwelle |
|---|---|---|---|
| task.latency_ms | Wall-Clock-Dauer vom Task-Eingang bis zum Terminal State. | p50, p95, p99 per Skill | p95 > 2× Baseline |
| task.cost_eur | Total Cost (Model + Tools) per Task in EUR. | Sum per Agent / Skill / Tag | Cost-per-Task > Budget |
| task.tokens_in / tokens_out | Input- + Output-Tokens per LLM-Call. | Sum per Model | Plötzlicher 50%-WoW-Anstieg |
| eval.score | Score aus Regression-Eval gegen task-spezifische Test-Cases. | Min, Mean per Skill-Version | Score-Drop > Schwelle blockt Deploy |
| safety.flag_rate | Anteil der Tasks, die der Safety-Classifier flaggt. | Rolling 1h, 24h | > Baseline + 2σ |
| tool.error_rate | Anteil der Tool-Calls mit Error-Return. | Per Tool, rolling 5m | > 5% sustained |
| human_handoff.rate | Anteil der Tasks, die zu menschlicher Freigabe eskaliert werden. | Per Skill, daily | Plötzliche Änderung indiziert Skill-Drift |
| skill.regression_delta | Eval-Score-Veränderung nach Skill- oder Modell-Update. | Per Deploy | Negatives Delta blockt Promotion |
KPIs, die Operators wirklich nutzen
Per-Call-Metrics sind nützlich fürs Debugging. KPIs sind, was du vor einen Sponsor oder Board stellst, um zu zeigen, ob das Agenten-Programm zahlt.
Cost per resolved Task
Total Spend (Model + Tools + Human Review) geteilt durch Tasks, die einen Terminal-Success-State erreichen. Vergleichbar direkt mit Human-Only-Baseline.
Mean Time to Human Escalation
Wie lange Agenten autonom arbeiten, bevor ein Task übergeben wird. Steigend = Skill-Drift; fallend = wachsende Autonomie.
Skill Regression Delta nach Deploy
Eval-Score-Veränderung zwischen aktueller und vorheriger Skill-Version. Fängt Modell-Upgrades, die Verhalten still degradieren.
Human Approval Acceptance Rate
Anteil der vom Agenten vorgeschlagenen Actions, die Menschen akzeptieren. Niedrige Rate = schlechtes Judgement; Rate von 1.0 über Zeit = Trust-Schwelle erreicht, Gate automatisieren.
Safety Incident Rate
Geflaggte Outputs per 1000 Tasks. Per Channel und Skill getrackt — um neue Prompt-Injection- oder Jailbreak-Patterns zu fangen.
Time to First Useful Output
Von Channel-Message-In bis zur ersten nützlichen Agent-Response. Die user-facing Latency, die bestimmt, ob Agenten real-time wirken.
Reliability — Evals als Deploy-Gate
Modelle ändern sich. Skills werden editiert. Ohne Eval-Gate ist jeder Deploy ein Coin-Flip. HybridClaw zeichnet echte Task-Runs als Trajektorien auf, spielt sie gegen neue Skill- oder Modell-Versionen ab und surft Regressionen, bevor sie Production erreichen.
- Trajektorie-Replay. Vergangene Runs werden zu Test-Cases. Neue Versionen müssen den Score erreichen oder schlagen.
- Skill-Scorecards. Per-Skill-Dashboard zeigt Pass-Rate, Latency und Cost über das Eval-Set. Operators sehen auf einen Blick, ob ein Skill production-ready ist.
- Deploy-Gate. Konfigurierbare Schwellen — Score, Latency, Cost — blockieren Promotion automatisch. Kein Mensch im Deploy-Loop, außer eine Regression tritt tatsächlich auf.
- Content-addressed Rollback. Jede Skill-Version ist content-addressed. Rollback ist ein Command, deterministisch und auditierbar.
Cost Control
Agenten-Plattformen können Modell-Budgets schnell verbrennen. HybridClaw macht Cost zur first-class observable Metric — gemessen per Agent, per Skill, per Task — und zeigt die Hebel, die Operators brauchen.
Model Routing
Simple Tasks an günstigere Modelle, komplexe an leistungsfähige — basierend auf Cost-per-Quality, gemessen durch Evals.
Per-Agent-Budgets
Soft- und Hard-Caps per Tag / Woche / Monat. Soft-Cap warnt, Hard-Cap stoppt neue Tasks bis aufgehoben.
Cache-Layers
In-Memory, on-Disk und Shared-Cache für Skill-Outputs und Retrieval. Cache-Hits kosten nichts.
Trajektorie-Pruning
Skills, die konsistent Token-Budgets überschreiten, werden für Refactoring oder Context-Kompression geflaggt.
Cost-Reports
Daily / Weekly Cost-Reports per Agent und Skill, exportierbar als CSV.
Cost-per-Outcome KPI
Total Spend gegen Business-Outcomes (gelöste Tickets, generierte Leads etc.) tracken — nicht nur rohen Token-Verbrauch.
Safety-Telemetry
Safety ist kein Output-Filter — es ist ein kontinuierliches Signal im gleichen Telemetry-Stream wie Latency und Cost. Operators sehen Safety-Incidents neben den Actions, die sie verursacht haben, mit vollständigem Audit-Trail.
- Jeder geflaggte Output wird mit der Trajektorie geloggt, die ihn erzeugt hat — Post-Incident-Review dauert Minuten, nicht Tage.
- High-Impact-Actions (Transfers, externe Mails, Deletes) verlangen menschliche Freigabe — konfigurierbar per Skill, audit-gelogged.
- Tamper-evidentes Audit-Log: jede Action chained und content-addressed. Operators können beweisen, was ein Agent gemacht hat, wann, und unter welcher Autorität.
- EU-gehostete Control Plane. DSGVO- & AI-Act-konform by Design.