Trust & Compliance
Audit-grade observability for AI agents
Every action an agent takes is recorded as a tamper-proof trajectory. Every skill has a measurable score. Every approval has an audit trail.
Why auditability is different for agents
A chatbot answers questions — an AI agent acts: it sends emails, writes to CRM records, calls APIs, transfers money. For finance, legal and IT teams that means: every single action has to be traceable, verifiable, reversible. HybridClaw treats every agent run like a banking transaction trail: time-stamped, signed, queryable, gap-free.
Six audit building blocks that ship with HybridClaw
These pieces work together — not as a bolted-on logging layer, but as part of the runtime.
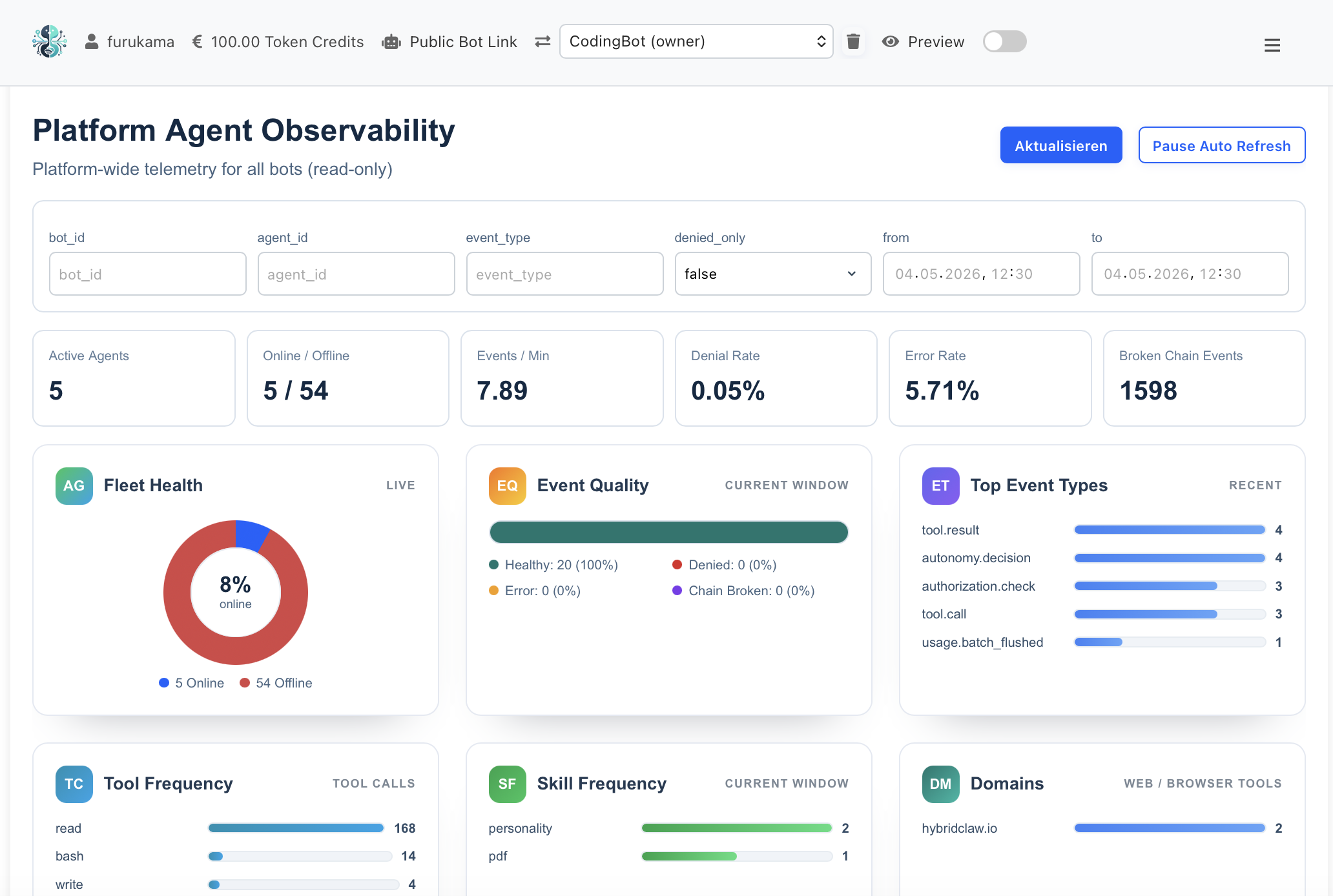
Gap-free action logs
Every tool call, every model response, every skill invocation is captured with input, output, latency and cost. Hash-chained so tampering is detectable.
Human-in-the-loop approvals
Skills can mark actions that require human approval (payments, contract changes). Approver, timestamp and reasoning are part of the audit trail.
Automatic PII redaction
Personal data is detected and masked on the way into logs and external models. The audit trail stays complete without exposing sensitive data.
Skill scorecards & evals
Every business skill is evaluated against workflow-specific test cases. Performance, stability and regressions become numbers you can verify.
Replay & rollback
Trajectories can be replayed step by step. Misguided actions can be rolled back where downstream systems permit it.
RBAC & encrypted secrets
Agents never see credentials in clear text. Role-based access defines who can do what — every privilege escalation is itself audited.
What ends up in the audit log
- Agent and skill identity. Which agent in which version with which skill (including a skill hash) performed the action.
- Input and context. The message or trigger that started the run, plus the relevant memory and RAG context.
- Tool calls. Every API call, browser action and DB query with parameters and responses.
- Model decisions. Which LLM, which prompt, how many tokens, what latency and what cost.
- Approvals. Who approved, who rejected, when and with what reasoning.
- Outcome. Success or failure, external status codes, final state of the affected system.
Without an audit layer vs. with HybridClaw
What happens when an agent makes a mistake in production?
With HybridClaw
- Trajectory shows exactly which input led to which action
- Responsibility is clear (agent version, skill, model)
- Skill score reveals whether regressions were measurable before
- Rollback and replay are possible
- Compliance report ready in minutes
Without an audit layer
- Logs scattered across model providers, tools and databases
- Reproducing an error can take days
- Silent model drift only surfaces through customer complaints
- Manual damage control, no defined rollback
- Audit requests require engineering time
"HybridClaw is selling the equivalent of a TÜV seal of approval for autonomous agents."
Audit questions we hear a lot
Are the audit logs stored in a GDPR- and AI-Act-compliant way? +
Yes. Logs are stored in EU hosting (or self-hosted with you), with configurable retention policies, automatic PII masking and defined deletion windows. HybridClaw captures the AI-Act-relevant fields (model, input hash, decision path, accountable party) systematically.
Who can view the audit logs? +
Access is governed via RBAC. Typical roles: compliance officer (read access to all trajectories), skill owner (access to owned skills), auditor (read-only on aggregate reports). Every read itself is logged.
How is log tampering prevented? +
Logs are hash-chained (every entry includes the previous entry’s hash) so later changes are detectable. In Managed Cloud, hashes are also periodically mirrored to an external append-only store.
Can we reuse trajectories for model training or evals? +
Yes. Trajectories are the raw material for skill evals, regression checks and agent CVs. With consent they can also feed fine-tuning or custom eval sets — after PII redaction.
Does this work in self-hosted installations too? +
Yes. The audit building blocks are part of the open-source runtime. In self-hosted deployments all logs stay exclusively on your infrastructure. Managed Cloud adds dashboards, long-term storage and external hash mirroring.